GenAI Image Model Training
Introduction
This post will really just be a compilation of my personal notes, where I've explored the essential concepts of generative image models, including training hyperparameters, model semantics, and practical insights to help you train a model yourself. Whether you're employing presets or experimenting with advanced configurations, I hope these notes make your journey into utilizing these tools a little smoother.
Preface and Experience
This collection of notes on image model training with KohyaSS originated in a pocket-sized notebook and is continuously evolving. Expect ongoing revisions as I condense key information to serve as a fundamental resource.
In my spare time, I've trained over 2,000 generative image models, primarily using the Stable Diffusion architecture. It's important to emphasize that I am self-taught in the realm of machine learning. Much of my understanding has been formed through a long process of iterative experimentation.
Dive into Deep Learning
For a more comprehensive exploration of deep learning, I recommend you check out:
- DeepLearning.AI with Andrew Ng
- Course.Fast.AI with Jeremy Howard
These resources will provide you with a much better understanding of the foundations of deep learning, as well as the hyperparameters involved in training models yourself.
Model Semantics: LLMs vs. Computer Vision
Before going head-first into generative image models, there are a few key points I'd like to make. When working with machine learning models, it's crucial to understand the differences between different data modalities. In this case, between large language models (LLMs) and computer vision models. LLMs process and generate text by learning from massive datasets of written language, enabling them to predict the next token in a sequence, handle long-range context, and even translate text.
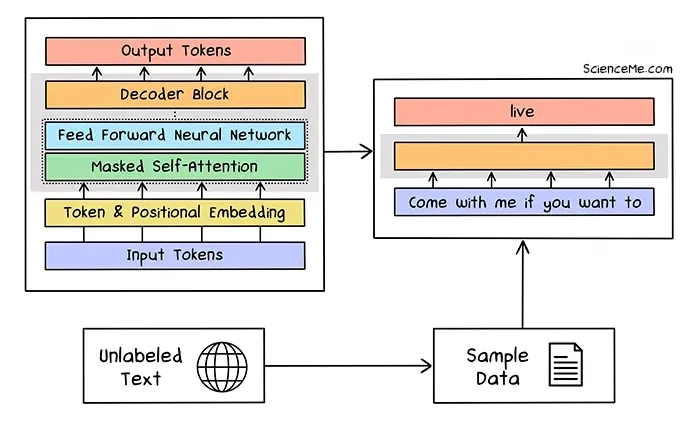
In contrast, traditional image classification models use visual data, typically RGB values, to recognize patterns and categorize image features based on assigned labels. Advanced vision models like Vision Transformers (ViT) and CLIP push beyond traditional classification tasks by bridging visual and textual understanding, although their focus remains distinct from that of LLMs.
Prompting
To preface, as datasets are re-captioned using advanced techniques and larger models, generative performance continues to grow. The notes below may not be as important at a later date.
A prompt is typically text-based conditioning data provided to a generative model's input. Image models are trained on large datasets of image-caption pairs, not large amounts of conversational text. When prompting image models, it's generally best to use language that resembles image captions rather than conversational text.
For example, instead of a verbose prompt:
"Please create a photo of a beautiful landscape, picturing a large grassy field, with a bright blue sky and a beautiful sun shining brightly overhead. Add an artistic flair to the image, giving it an illustrative touch with hints of aesthetically pleasing qualities. Make sure the image portrays a beautiful scene filled with rich details and include elements of sci-fi and poetic themes throughout the image."
Try a more concise, caption-like prompt:
"Large grassy field, beautiful day, detailed, illustrative, aesthetic, sci-fi, poetic musings"
This approach helps prevent using excessive tokens, and stops you from pulling the model in various directions through the embedding space. See 3Blue1Brown's video on visualizing attention in transformers!
Note that this may not apply to apps/services like Midjourney, as many platforms often alter user prompts and the models performing the generation process in some way. Without a local, open-source environment, it's uncertain what prompts or conditioning data the generative models receive.
LoRA Learning
Understanding LoRAs
LoRA (Low-Rank Adaptation) is a method used to fine-tune models with fewer trainable parameters. All this really means is we take a large base model, and we train over the top of small pieces of that model, rather than the whole thing. Instead of adjusting all the model's weights, LoRAs introduce a small set of trainable matrices for each layer, significantly decreasing the number of parameters and making it more computationally efficient for fine-tuning large models on consumer hardware.
Learning Targets
There are two main learning targets:
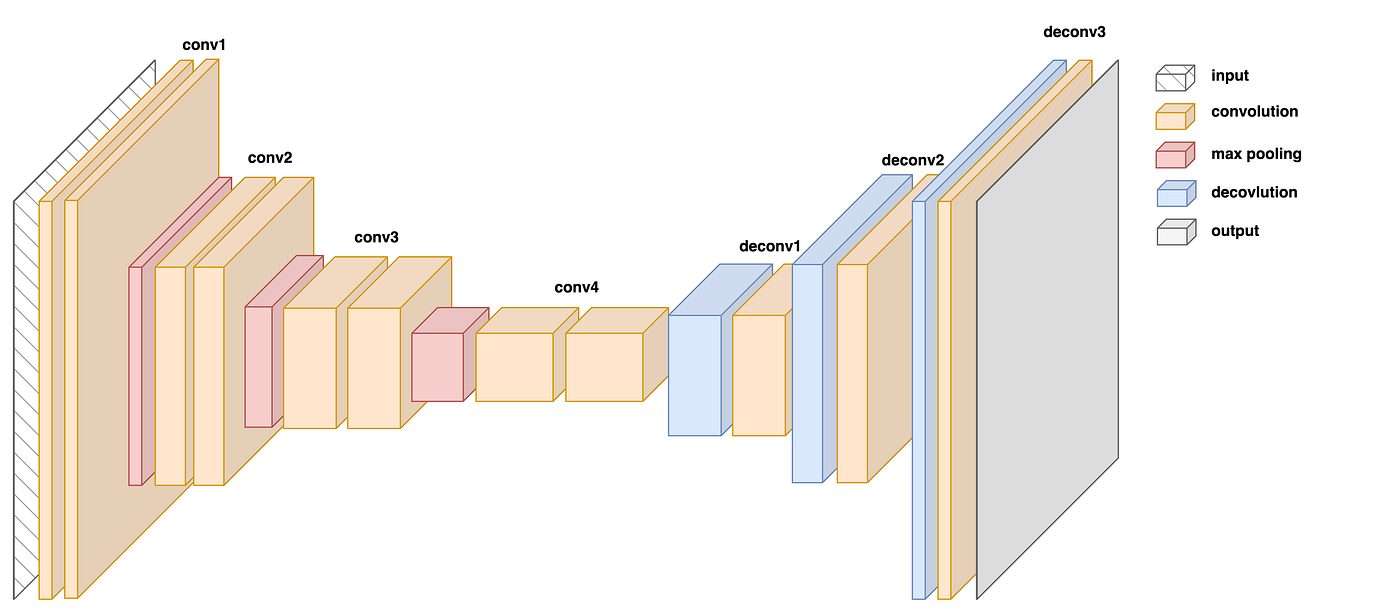
- U-Net: Consists of downsampling, bottleneck, and upsampling paths, responsible for processing image data and generating output images. If you wish to learn more about this, see the links provided below.
- Text Encoder: Converts text prompts into vector representations (numbers in a matrix) shared by all attention blocks in the U-Net, playing a crucial role in the "Cross Attention" mechanism.
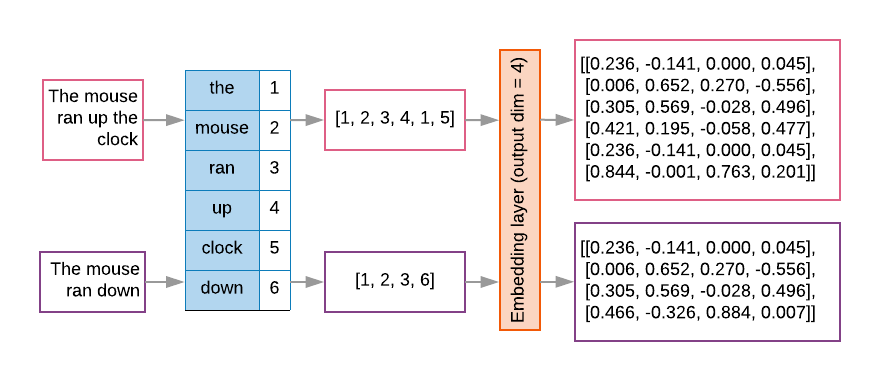
Most often, the U-Net uses a single text encoder. However, with architectures such as that of the FLUX generative image model family, it's not uncommon to see multiple text encoders utilized to improve model performance.
Although the text encoder in Stable Diffusion models is typically considered "finished," it can be further tuned using LoRAs.
DyLoRA, Lo-con, LoHA? - LoRA Types
KohyaSS supports a range of LoRA types, each with specific use cases. Choosing the optimal type depends on the data you have prepared, your desired effect on the outputs, your hardware, and other factors. Experimentation is vital in machine learning due to the lack of a one-size-fits-all configuration.
There's nothing wrong with using the standard LoRA type. Explore other types if you encounter specific issues or wish to experiment.
DyLoRA (Dynamic LoRA)
DyLoRA training enables simultaneous learning across various network ranks within a defined maximum rank, helping find the optimal rank for your specific data.
LoHA (Low-Rank Hadamard Adaptation)
LoHA is designed for smaller hardware setups, producing slightly lower fidelity compared to standard LoRA and learning feature representations differently.
Lo-con (Low-Rank Convolution)
Lo-con extends learning to the ResNet blocks within the U-Net, enhancing the model's ability to capture subtle patterns. I have limited experience with this configuration.
Training Parameters
Batch Size
Batch size defines how many images are processed concurrently during training. Larger batch sizes can speed up training, but it may reduce individual feature precision. To put this simply, you may not capture some finer details from the images you provide in your dataset. Adjust the learning rate accordingly—if you double the batch size, the learning rate should be doubled to maintain effective training. Larger batches capture broader patterns (think overall style or tone of the images), but it ensures diversity to avoid overfitting (recreating 1:1 features from your images).
- How to maximize GPU utilization by finding the right batch size - David Clinton, Shaoni Mukherjee - PaperSpace
- Effect of batch size on training dynamics - Kevin Shen - Medium
- Optimizing LoRA Training with Various Batch Sizes - Toolify
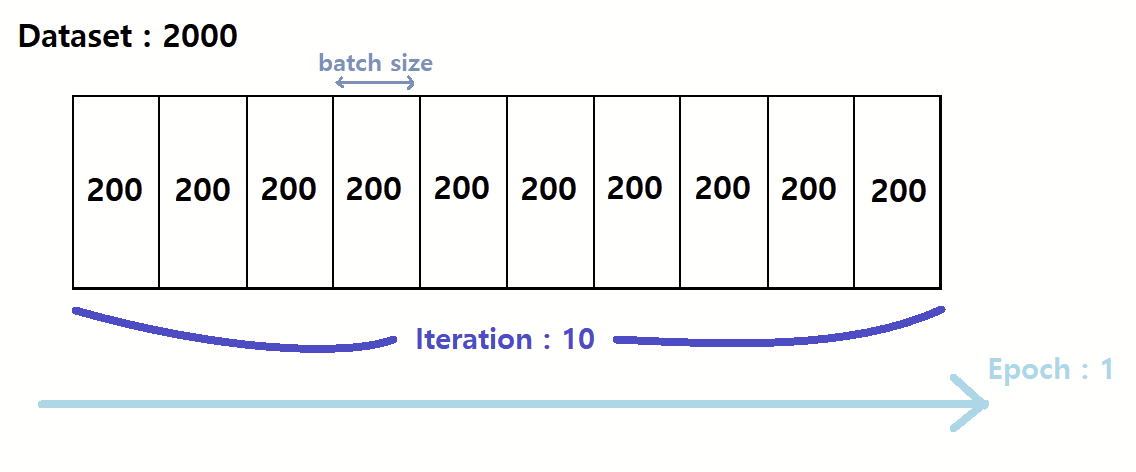
Repeats vs Epochs
In KohyaSS, repeats and epochs serve different roles:
-
Repeats: Define how many times each image is processed within a single epoch. For example, setting repeats to 25 means each image is trained 25 times during one epoch.
-
Epochs: Represent the number of full passes through the dataset. After each epoch, the model has seen the entire dataset once (or more if repeats are used).
The balance between these two arguments is really important. Typically, you'd only really increase the number of repeats with sparse datasets. That being said, LoRAs can learn quite effectively even on small sample sizes (with the right configuration), while epochs have a more direct impact on the model's weights themselves, thus the way in which it learns.
- Understanding LoRA Training - Dreams Are Real - Medium
- Epoch vs. Batch vs. Iteration in Neural Networks - Sujatha Mudadla - Medium
Number of Regularization Images
Regularization images can be beneficial but aren't always necessary. A common guideline is to set their number equal to the training images multiplied by the number of epochs. I've achieved good results both with and without them, but will typically use them if I'm trying to train over a large dataset (1,000+ images).
- My LoRA Experiments - Regularization Images - zoomyizumi
- My Findings on the Impact of Regularization Images...
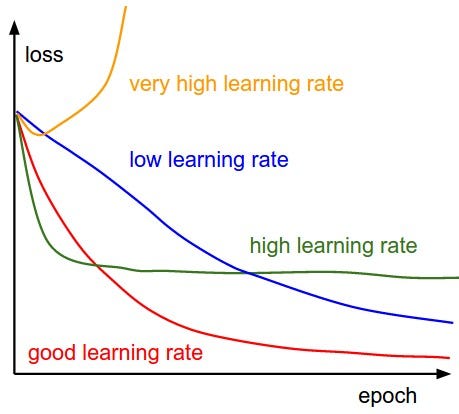
Learning Rate
The learning rate (LR) determines how quickly the model's weights are updated. It can vary depending on factors like batch size, dataset complexity, and model architecture. Adjust the learning rate iteratively based on model performance. The default of 2e-4 is usually where I start, but I adjust it frequently based on the number of epochs, network alpha, and batch size.
- Understanding LoRAs - LR Schedulers, NDim, Alpha - Dreams Are Real - Medium
- Effect of Rank, Epochs, and Learning Rate on Training Textual LoRAs - RunPod
Network Alpha
Network alpha is a scaling factor that fine-tunes the magnitude of weight updates. It varies depending on the LoRA method and optimization algorithm (commonly AdamW).
Mixed Precision Training
KohyaSS supports mixed precision training, reducing memory usage and improving performance using lower precision formats like FP16 and BF16. All FP32/FP16 means is typically how the weights are stored in the model- 32 digits or 16 digits.
- FP16: Cuts memory requirements in half, but can cause numerical instability.
- BF16: Retains FP32's 'numerical range', offering a good compromise. See the documents below.

Random Seeds
Seeds determine aspects like image processing order and noise patterns. I typically use an arbitrary value for consistency across training runs, like 42.
Cache Latents
Caching latents pre-compresses images into their latent space, speeding up subsequent training and reducing VRAM usage. It limits augmentations to flip augmentation only but is useful for repeated training on the same dataset. This is something I tend to keep on, because I find myself frequently adjusting training parameters and re-training until I find a good valley my data is sitting in.
LoRA Network Rank
The network rank defines the number of neurons in the hidden layer of the additional neural network used in LoRA learning. Experimentation is key to finding the optimal rank. Larger networks means your network will "store" more information. However, this may not be a good thing, because it means the model is more likely to learn undesirable features from the images. Additionally, it may lead to overfitting if left too small. 64 is a good place to start.
LoRA Network Alpha
LoRA network alpha prevents weights from becoming too small, ensuring effective learning. It should not exceed the network rank. Changes to this value will have to be reflecting in the learning rate.
Some notes:
Changes to your alpha influence your optimal learning rate. If the network alpha is 16 and the network rank is 32, the learning rate is halved (16/32). Adjust parameters as needed.
Preventing Text Encoder Training
Updating the text encoder can lead to overfitting. Specify a stopping point as a percentage of total steps.
Advanced Configurations for LoRA Training
Weights, Blocks, and CONV Settings
Weights
weights determine learning rate weights for each U-Net block. The threshold value prevents neural networks from being added to blocks with weights below it.
Blocks: Bdim and Balpha
blocks specify dimension (Bdim) and alpha (Balpha) values for each U-Net block. Some blocks are ignored during learning.
CONV: CONVdim and CONValpha
LoRA updates convolutional neural networks within blocks. CONVdim and CONValpha control CONV layers.
LoRA Block Weights
LoRA block weights control block influence during training. The U-Net Middle Block typically has higher weight.
Token Padding
token padding ensures input sequences have the same length.
Weighted Captions
weighted captions use syntax like token:1.3 to assign token weights, useful for complex captions.
Prior Loss
prior loss balances training data and regularization images. Adjust based on your needs.
Learning Rate Settings
LR Num Cycles
Specifies cycles for cosine with restarts scheduler.
LR Power
Used with polynomial scheduler; controls learning rate decrease.
Saving and Tokenization
Save Last N Steps
Allows model saving during training at specified intervals.
Keep N Tokens
Determines tokens to keep when shuffle captions is on.
Clip Skip
Set clip skip to 2 if the base model is a novelAI model.
Max Token Length
Specifies total tokens allowed in captions.
Data Loading and Attention
Persistent Data Loading
Keeps image data in memory for faster training.
Memory Efficient Attention
Suppresses VRAM usage; slower than xformers.
Xformers
Trades attention blocking for reduced VRAM usage.
Data Augmentation
Color Aug
Increases images using color augmentations.
Flip Augmentation
Useful for learning symmetrical concepts.
Noise Settings
Min SNR Gamma
Controls noise strength; optimal value is 5.
Noise Offset Type
Determines noise addition method; multires adds complexity.
Noise Offset
Applicable when LoRA type is Standard; adjusts noise levels.
Adaptive Noise Scale
Adjusts noise based on image noisiness.
Multires Iterations
Determines resolutions for multires noise.
Multires Discounts
Weakens noise per resolution for multires noise.
Caption Dropout
Dropout Caption Every N Epoch
Specifies epochs after which training occurs without captions.
Rate Caption Drop
Determines percentage of images trained without captions.
By configuring these settings, you can fine-tune LoRA training to suit your requirements and optimize model performance.
Final Remarks
I hope this guide and the additional resources help you train great models. FLUX has captured my attention, and I'm exploring creating training applications with custom configurations. Updates to this guide may come as I delve further into deep learning and generative image models.
- Zac